Hybrid Storage Project
Project Concluded: Septmber 02, 2021
DB Reference: dc_stor_hybrid
Last Updated: September 26, 2023

Introduction
Efficient storage is crucial for a small data center. As more servers and services are added, storage need grows. But, most allocated disk space for each virtual machine (VM) often goes unused and still takes up space. While Thin Provisioning is available, it lacks flexibility in data management and can decrease performance.
To improve disk utilization, a hybrid storage project was launched. It focuses on providing a centralized, dynamic, and expandable network attached storage(NAS) system using a 40G LAN. The system includes a hybrid storage solution for hot and cold data.
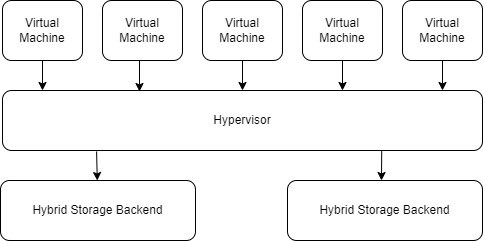
Specification & Structures
As of April 2023, the system has the following specification:
Storage Server: 4+ * 24 Core CPU & 16G Memory Bare-Metal Server
Disk Capacity: Each server was equipped with 72TB RAID 6 array.
RAID Controller: HP Smart Array P840 with 4G cache.
RAID Policy: Write-back.
Tape Library: HP MSL2024 Tape Library + LTO 6 Drive
Detailed Description
The aim of this project is to boost disk utilization by transferring cold data to a tape library and reducing wasted space from virtual disk initialization and preallocation.
The project consists of four components: a cluster of Windows storage servers, a tape library, a fast 40G LAN, and a set of access protocols.

High-Performance Storage Server
Storage Solutions
The backbone of storage is the hardware that stores data. A goal of 430TiB of storage space was established(required by the Genetic Analysis Project), and I researched ways to reach it. I've considered three options:
- 1. Large single server: Such as the 6049SP-DE1CR60 from Supermicro, which can have up to 60 disk bays in just one server.
- 2. Expandable OEM system: For example, the DELL M3000 + M1000, which can be expanded with additional storage enclosures.
- 3. Distributed storage: Multiple individual storage servers, each with up to 12 disk bays.
Based on past experience and research, the advantages and disadvantages of these systems are clear:
| Solution | Overall Price | Expandability | Performance | Disk Model | Fail Safe |
|---|---|---|---|---|---|
| Singel High-Capacity Server | Moderate | Software Cluster | Limited by single Storage Contoller & NIC | Unlimited | A single controller failure will brought down the entire server. |
| OEM Expandable System | High | Hardware Disk Enclosure | Limited by single Storage Controller & NIC | OEM only | A single controller failure will brought down the entire cluster. |
| Distributed Storage | Moderate | Software Cluster | Multiple Controllers & NIC | Unlimited | A controller failure may brought down part of the storage cluster. |
When the project started, the main goal was to provide storage for the Genetic Analysis Project, making storage cluster performance crucial. Thus, a single storage controller or NIC may not provide sufficient throughput.

A centralized storage system is feasible, but the project doesn't require all files to be stored in one location. For example: files are separated into categories like downloading, preprocessing, analysis, storage pending, and results. Also, Non-RDMA supported access (due to driver unavailability) requires high single-core CPU performance, making a distributed storage system with multiple CPUs a better choice.
For the future, a dedicated storage system is just for storage, but a group of storage servers can serve other purposes. If the storage backend is reorganized in the future (e.g. full NVMe storage), these servers can be repurposed for other tasks.
Thus, the hardware solution selected was a distributed storage system of multiple storage servers connected by a fast 40G LAN.
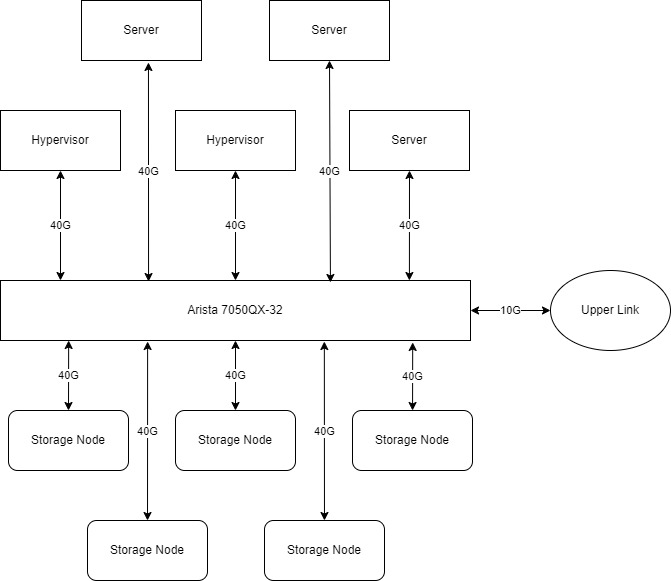
Hardware
With the storage solution in place, the next step is choosing the hardware. This is a flexible process as the number of servers depends on the capacity of each server. The capacity of each server depends on the number of disk bays and the size of single hard drives (HDDs). However, the most cost-effective HDD models may not always be the best overall value. It's possible to choose a more expensive, high-capacity drive to increase the capacity of a single server, reducing the total number of servers(and cost), which is preferable even if it costs the same.
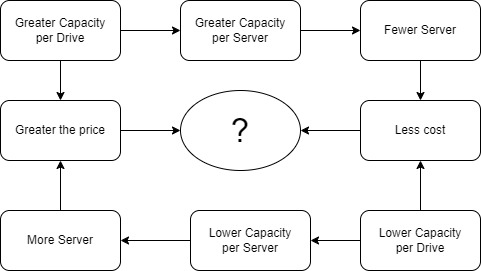
Server Models
Before considering details like RAID controllers, the server model must be chosen. As we mainly use 3.5 inch HDDs, only 2U or 4U servers should be considered. With no brand preference, price is the deciding factor. The chosen model is the HP ProLiant DL380G9 with 12 * 3.5 inch drive bays.

Storage (RAID) Controller
The DL380G9 has two common raid controllers: P840 and P440. After comparing their specifications in detail, I found that the P840 has better performance than the P440 with an acceptable price difference. So, the P840 was chosen as the raid controller.

Disk Model
Capacity is the priority, so pure HDDs will be used for the storage server (all other servers use pure SSD arrays - refers to the genetic analysis project for more information). It's important to note that hard drive manufacturers are incorporating SMR technology in newer disks, which increases data density but decreases performance and reliability. Therefore, I prefer CMR disks. After comparing prices, two models from Western Digital were selected for a final comparison: HC320 and HC530."
The HC320 is a conventional HDD with 8TB capacity. The HC530, however, is a helium HDD with 14TB capacity. Both models use CMR and have a similar price per terabyte.

The HC530 might seem like the better choice based on price, but I realized that long-term usage over 3 years can result in helium leakage. In a traditional data center, drives are regularly replaced, so helium leakage is not a concern. Retired drives usually can still work well and can last another 5-6 years. I want to use the drive for as long as possible, likely at least 6-7 years, so helium leakage (which is hard to detect and can cause disk failure) must be considered.

Unfortunately, I couldn't find enough information about this issue online. This might be because the history of helium drives only goes back 7 years to 2013. In the end, I chose to go with the HC320.
I've heard that using the same batch of disks for RAID is discouraged as it can lead to simultaneous disk failure before the array can be rebuilt, especially near the end of a disk's lifespan. However, that issue is outside of my current scope, and I have to skip that for now.
CPU
The DL380G9 is compatible with Intel Xeon E5-2600 V3 and E5-2600 V4 series CPUs. These models are somewhat outdated but still have sufficient power for storage purposes.
A storage server doesn't need much computing power, so an energy-efficient model would be ideal. The V3 is the last generation of Intel's 22nm CPU and the V4 is the first generation of Intel's 14nm CPU. In general, the V4 series uses less energy than the V3 series.

Next, I need to select a specific model. I plan to use RDMA technology on the storage servers. However, for services that don't support RDMA, the single-core frequency of the CPU is critical for I/O performance. I may also perform compression and decompression tasks directly on the storage server, as having another machine do it over the network is not practical. As compression tasks are often multi-threaded, the ideal CPU model should have a large core count, a high single-core turbo frequency, and a low TDP.
After considering the price, the Xeon E5-2650 V4 was selected. This CPU has 12 physical cores, a 2.9 GHz turbo frequency, and a TDP of 105W. Each storage server will be equipped with two E5-2650 V4s
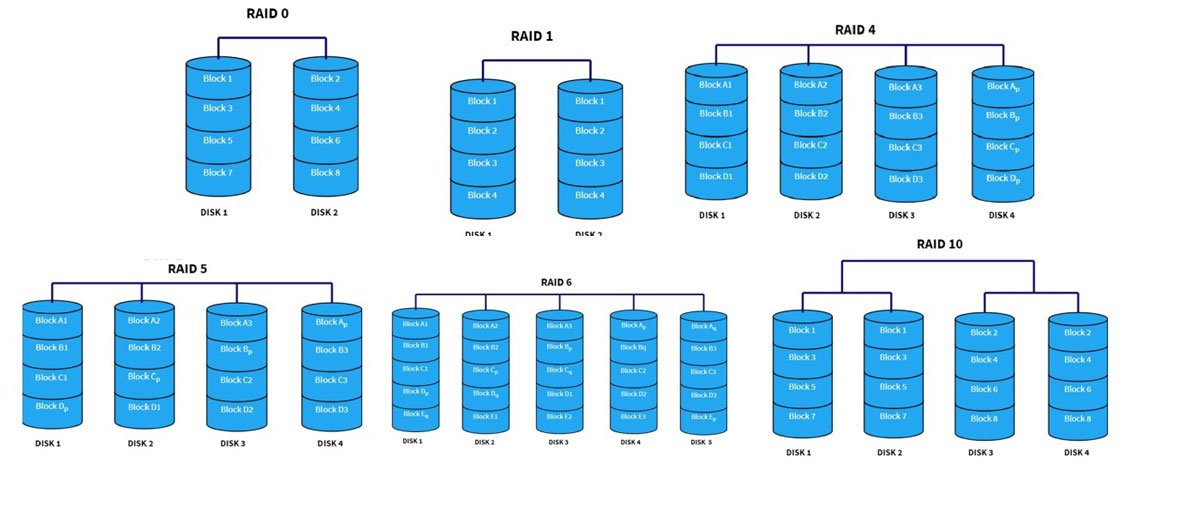
Configuring RAID
Having only physical disks is not enough, RAID must be configured before the array can be brought online. Each server has 11 * 8 TB HDDs (the remaining slot is used for the SSD hosting the OS), so redundancy is necessary. Common redundancy configurations are RAID 1, RAID 10, RAID 5, and RAID 6. While I considered options beyond these, they are not shown here for simplicity. RAID 1 provides only 8 TB capacity at the cost of 11 disks, so it's not suitable. RAID 5 can only handle one disk failure, which may not be enough for an array of 11 high-volume disks. Of the remaining two options, RAID 6 was selected for its balance between capacity and safety(at most two disks fail), with a relatively higher performance. RAID 10 was not chosen because it requires an even number of disks and can only provide half of the total capacity, resulting in 40 TB compared to 72 TB with RAID 6.
Additionally, since our raid controller was power enough, write-back policy was set to utilize the on-board cache and provide a better performance.
Tape Library
We have multiple storage servers, but that's not enough. Most of the data is cold and does not need real-time access (likely never). A cost-effective long-term storage solution is required.
Feasibility
Initially, there were two plans for cold data: using hard disks and disconnecting them from the server or using tapes.
Tapes are much cheaper than hard drives, but tape drives are more expensive than the entire storage server. Additionally, tapes have slow (or no) random access performance. Tapes only have an advantage over hard drives when the amount of data is larger than a certain threshold.
Using a web crawler, we estimated the total amount of cold storage required to be about 430 TiB(this was later corrected to about 2000 TiB). Based on the price, tapes will have an advantage over hard drives starting at 340 TiB. Thus, a tape system will be part of the storage system.

Unlike storage servers, there are not many options for tape storage systems. I chose the cheapest OEM model at the time, the HP MSL 2024 Tape Library with HP's LTO 6 drive.
A database and search tools for the content of each tape were also deployed. For more information, please refer to the Genetic Analysis Project

Sharing Policy
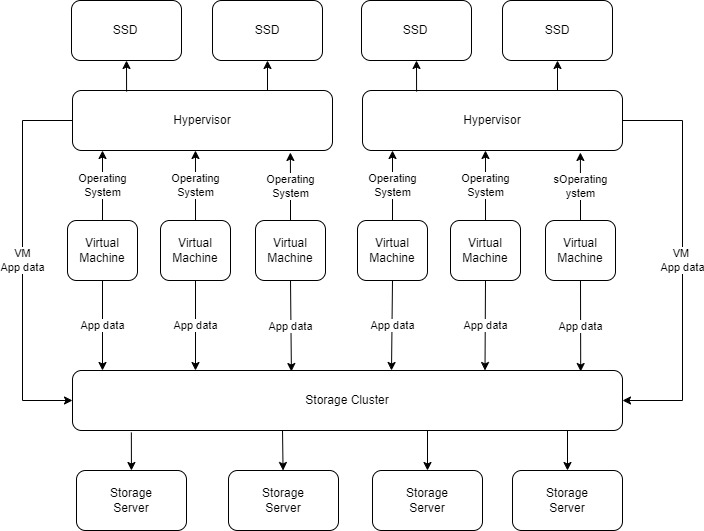
For Hypervisors
In the past, when creating a new virtual machine on a hypervisor, a data store partition was also assigned in addition to the OS disk. This occupied precious SSD space, especially because the actual used space was often far less than what was allocated. Existing technology like Thin Provisioning, in this case, was not effective in efficiently reclaiming space.
Most data storage needs within each virtual machine (VM) can be met with a standard hard disk drive (HDD). So, when a new VM is created on any hypervisor, it is given 16 GB of space for Linux and 40 GB for Windows, which is sufficient for just installing the operating system.
For the data partition, if the application supports Network Attached Storage (NAS), a remote share will be mounted using CIFS utilities. The storage capacity of this share can be adjusted in real-time on the storage system. If the application doesn't support NAS, a disk will be added to it from the hypervisor, which is still hosted on the storage cluster using Network File System (NFS).
This significantly minimizes unused SSD space and enables hosting more virtual machines on the hypervisor. Additionally, migrating virtual machines is no longer a headache as only the operating system disk needs to be migrated. As long as the system can still access the storage cluster, it will resume operation smoothly.
For Domain Users
All of the storage servers were using Windows Server 2019 at the time. Windows may not be the most reliable, but it provides excellent permission controls through Active Directory.
Currently, a 200 GiB personal folder for each member of the research group has been initialized on the storage cluster. This folder is mapped to their account through GPO policy. Whenever they log in to any machine in the domain, their personal folder is always available with a fast speed.
For other projects, a dedicated project drive has been initialized and mapped to project members' accounts through the GPO policy.
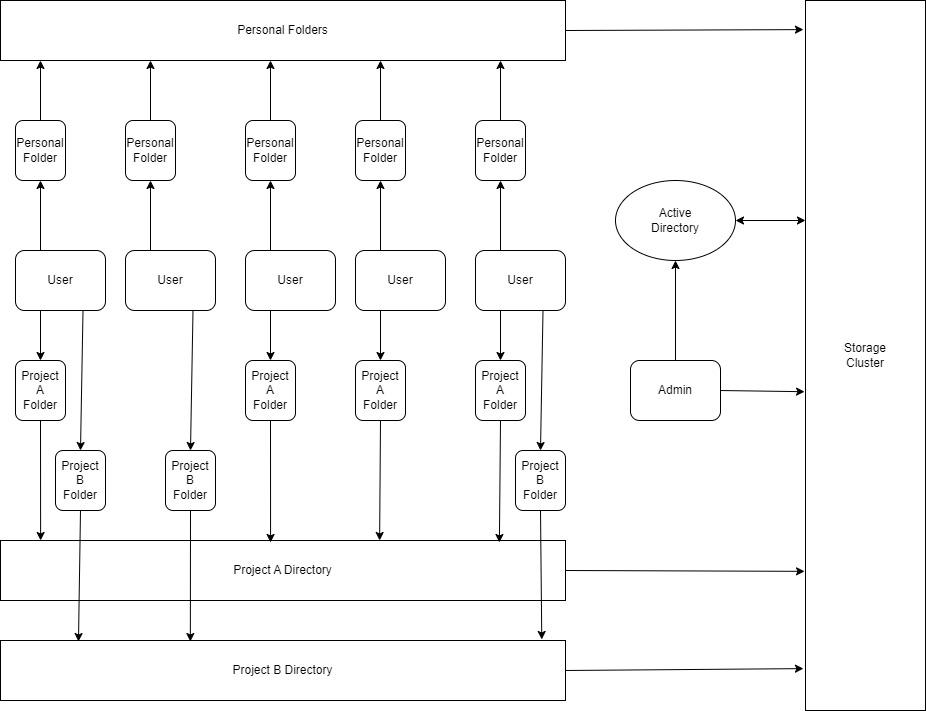
One advantage of this sharing model is that the capacity for each share is dynamic and can be adjusted in a matter of seconds without dealing with disk partitions. Also, since users rarely use all their available space and the total space for each storage server is huge (65 TiB in the system and 72 TB by disk), we can slightly over-allocate the space for each storage node without any issues.
Access Protocols
For most Windows systems, the default domain sharing was used, which was through the SMB 3 protocol.
For general Linux machines, CIFS was used.
For hypervisors, NFS was used as an alternative method of sharing disk space without configuring inside the virtual machine.
For all other scenarios where NAS storage is not supported, iSCSI was used to simulate a real system-level disk.
RDMA/RoCE
The 11-HDD RAID 6 array is fast enough for multiple I/O requests, but network speed is limited by the CPU processing each bit before it reaches the faster 40G NIC. RDMA solves this problem, and RoCE (RDMA over Converged Ethernet) was deployed since the network runs on Ethernet instead of Infiniband.
There's limited information online about RDMA/RoCE probably due to it mostly being used in large datacenters or corporate networks managed by professional IT staff. It took me a long time and I've tested multiple combinations of parameters before successfully getting it to work.
Once RDMA is operational, the CPU bottleneck is eliminated and network access for RDMA-supported servers is as fast as local storage.

The Future Work
- Replace the Windows OS with advanced storage solutions like GPFS (General Parallel File System). For more information, please refer to GPFS Project.
- To improve network throughput, Infiniband might be deployed in addition to Ethernet. For more information, please refer to the Infiniband Project.
- A plan is in place to create a full SSD storage system for hypervisors and other applications, aimed at improving SSD utilization. However, this involves a significant restructuring of the entire datacenter and requires further evaluation, so it has not yet become a formal project.