Computing Cluster

In preparation for our gene analysis project, a computing cluster was built to process over hundreds GBs of data everyday.
Hardware
- 3 * DELL R740 each with dual Intel Xeon Platinum 8269CY
- 1 * DELL R630 each with dual Intel Xeon E5-2678V3

Structure
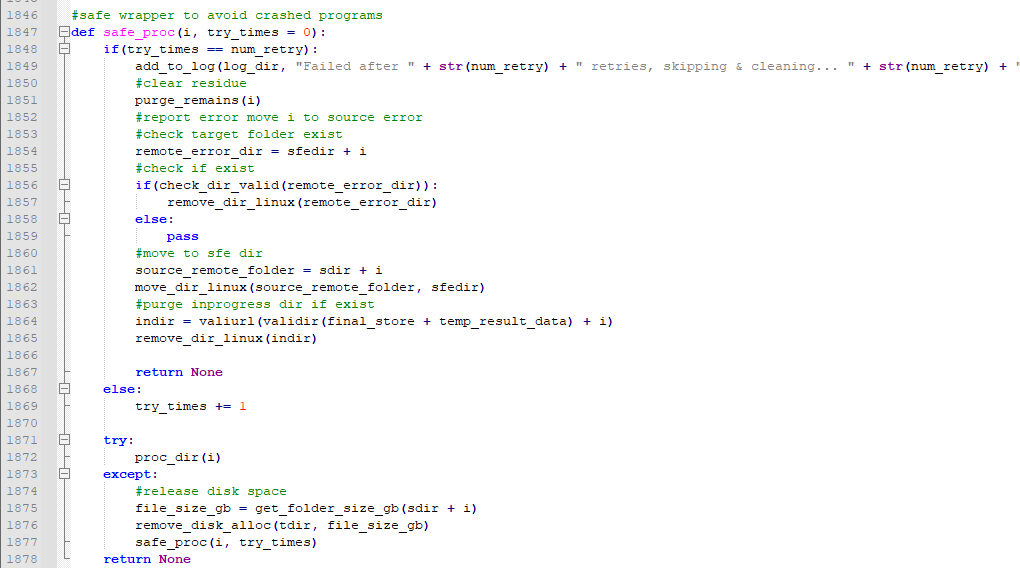
After received data from download/storage server, it was sent to preprocess at R630 machine.
Data was then assigned and distributed to R740 servers for computation.
Since data analysis time is directly proportional to its size, the scheduler will assigned each day's donwload to only one machine.
Entered the analysis server, data was first differentiate as single-end and pair-end sequencing.
The processing pipeline is roughly: single/paired checking - check and convert encoding to phred33 - extract scientific name - trim_galore(cutadapt & fastqc) - salmon - result validation & collection.
Results were collected again at the R630 machine and transfer to storage. Failed data will be retried 3 times before moving to failed directory at storage and will be processed on a case-by-case basis. There will be no temp storage at analysis servers
Code Snippets